






Quante volte sul lavoro prendiamo decisioni basate su un presentimento? Vediamo una media leggermente più bassa e pensiamo: ‘Ok, il nuovo metodo funziona’. Oppure notiamo un leggero scostamento e andiamo subito nel panico.
L’analisi dei dati serve esattamente a evitare questo: trasformare le sensazioni in certezze misurabili.
Quando lavoriamo con campioni piccoli e non conosciamo tutte le variabili della popolazione, il Test t di Student è lo strumento che ci salva letteralmente la vita. Non serve essere dei matematici per capirne l’utilità; basta capire che ci aiuta a rispondere a una domanda fondamentale:
la differenza che sto osservando è reale, o è solo rumore statistico?
In questo articolo vedremo tre esercizi pratici risolti, presi da scenari aziendali reali, per capire come applicare i test a una o due code e come interpretarne i risultati senza cadere in errore.
Esercizio 1: Il tempo di reazione del nuovo farmaco (Test t a un campione)
Testo dell’esercizio:
Un’azienda farmaceutica ha sviluppato un nuovo analgesico con un tempo medio di insorgenza atteso di 35 minuti. Su un campione di 20 pazienti, si rileva una media di 32.5 minuti con una deviazione standard di 6.8 minuti. Verificare se il tempo di insorgenza è significativamente diverso da quello atteso ([math]\alpha = 0.05[/math]).
Risoluzione
1. Definizione delle ipotesi
Siamo in presenza di un test bilaterale (a due code):
- H₀: [math]\mu = 35[/math] minuti (Il farmaco non presenta tempi diversi dalla media nota).
- H₁: [math]\mu \neq 35[/math] minuti (Il farmaco ha un effetto diverso).
2. Calcolo della statistica test
Poiché la varianza della popolazione non è nota e il campione è piccolo ([math]n < 30[/math]), utilizziamo il Test t di Student:
[math]t = \frac{\bar{x} – \mu_0}{s / \sqrt{n}}[/math]
Inserendo i valori:
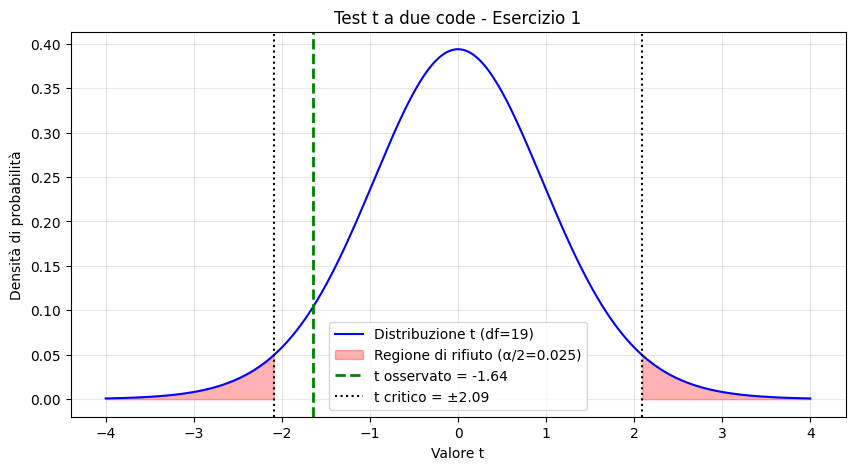
[math]\displaystyle t = \frac{32.5 – 35}{6.8 / \sqrt{20}} = \frac{-2.5}{1.5205} \approx -1.644[/math]
3. Valore critico e Gradi di Libertà
- Gradi di libertà (df): [math]n – 1 = 19[/math].
- Valore critico ([math]\alpha = 0.05[/math]): Consultando le tavole della distribuzione t per 19 df, il valore critico bilaterale è [math]t_{crit} = \pm 2.093[/math].
4. Decisione e Conclusione
Il valore calcolato [math]t = -1.644[/math] è compreso tra -2.093 e +2.093. Di conseguenza, cade nella regione di accettazione.
Conclusione: Non abbiamo prove sufficienti per rifiutare [math]H_0[/math]. Nonostante la media osservata sia più bassa (32.5), la differenza non è statisticamente significativa al livello del 5%.
Perchè questo esercizio ti deve interessare:
1. La Media è solo metà della storia
A prima vista, un miglioramento di 2.5 minuti (da 35 a 32.5) sembra un successo commerciale pronto per essere pubblicizzato. Tuttavia, la deviazione standard (6.8 minuti) agisce come un “filtro di realtà”: ci dice che il rumore di fondo nei dati è più forte del segnale di miglioramento che crediamo di aver trovato.
- Esempio pratico: Se un farmaco agisce in 15 minuti su un paziente ma in 50 su un altro, la “media” di 32.5 perde valore operativo perché il medico non può prevedere con certezza l’effetto sul prossimo paziente.
2. Evitare il “Falso Positivo” in R&D
In ambito Ricerca e Sviluppo (R&D) o Project Management, lanciare un prodotto basandosi solo sulla media aritmetica è un rischio finanziario enorme. Il test statistico ci impedisce di investire milioni in un processo che, alla prova dei fatti, non offre un vantaggio competitivo riproducibile.
- Significatività Statistica vs Pratica: Anche se avessimo trovato una differenza significativa (p-value < 0.05), dovremmo chiederci: “Risparmiare 2 minuti su 35 giustifica il costo di produzione del nuovo farmaco?”. La statistica risponde alla prima domanda, il management alla seconda.
3. Il ruolo della variabilità (Il “Rumore”)
L’esercizio insegna che la coerenza è spesso più importante della performance assoluta. Un’elevata deviazione standard indica che il processo non è sotto controllo o che la popolazione risponde in modo troppo eterogeneo.
- Lezione strategica: Prima di cercare di “abbassare la media”, spesso è più vantaggioso lavorare per “stringere la curva” (ridurre la deviazione standard), rendendo il risultato prevedibile e affidabile.
💡 Domanda di riflessione
Perché in questo esercizio abbiamo usato il test t di Student invece del test z? Quale proprietà della distribuzione dei dati abbiamo implicitamente invocato?
Risposta approfondita:
- Test t vs Test z: Abbiamo usato il test t perché la deviazione standard della popolazione ([math]\sigma[/math]) è ignota. In questi casi, stimiamo [math]\sigma[/math] usando la deviazione standard campionaria [math]s[/math]. Se avessimo usato lo z-test, avremmo sottostimato l’incertezza derivante dal piccolo campione ([math]n=20[/math]).
- Assunzione di Normalità: Abbiamo implicitamente invocato l’ipotesi che il tempo di insorgenza nella popolazione segua una distribuzione normale. Con campioni piccoli, il Teorema del Limite Centrale non è sufficiente a garantire la normalità della media campionaria, rendendo necessaria la verifica (o l’assunzione) che i dati originali siano gaussiani.
Esercizio 2: Efficacia di un corso di formazione (Test t unidirezionale)
Testo dell’esercizio:
Un’azienda vuole verificare se un corso di time management riduca la media delle ore lavorate sotto la soglia delle 40 ore settimanali. Su un campione di 15 dipendenti, si registra una media di 38.2 ore e una deviazione standard di 5.1 ore. Verificare l’ipotesi con [math]\alpha = 0.01[/math].
Risoluzione
1. Definizione delle ipotesi
In questo caso siamo interessati solo alla riduzione delle ore, quindi il test è unidirezionale sinistro:
- H₀: [math]\mu \ge 40[/math] ore (Il corso non ha ridotto il carico di lavoro).
- H₁: [math]\mu < 40[/math] ore (Il corso ha ridotto significativamente le ore lavorate).
2. Calcolo della statistica test
Utilizziamo il test t di Student per piccoli campioni:
[math]t = \frac{\bar{x} – \mu_0}{s / \sqrt{n}}[/math]
Sostituendo i valori:
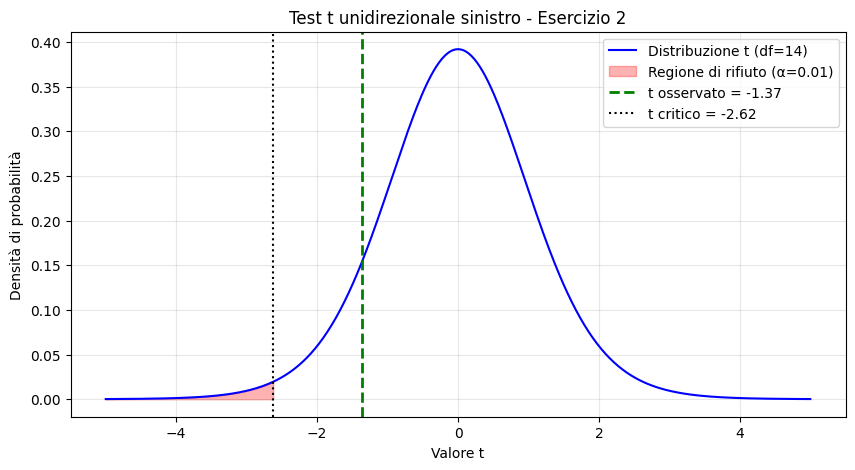
[math]\displaystyle t = \frac{38.2 – 40}{5.1 / \sqrt{15}} = \frac{-1.8}{1.3168} \approx -1.367[/math]
3. Gradi di libertà e valore critico
- Gradi di libertà (df): [math]15 – 1 = 14[/math].
- Valore critico ([math]\alpha = 0.01[/math]): Trattandosi di un test a una coda verso sinistra, cerchiamo il valore che lascia l’1% di probabilità nella coda inferiore. Dalle tavole: [math]t_{crit} = -2.624[/math].
4. Regola decisionale e Conclusione
Confrontiamo il valore calcolato con quello critico:
- Rifiutiamo [math]H_0[/math] se [math]t_{calc} < -2.624[/math].
- Poiché [math]-1.367[/math] è maggiore di [math]-2.624[/math], il valore cade nella regione di accettazione.
Conclusione: Non rifiutiamo l’ipotesi nulla. Al livello di significatività dell’1%, non c’è evidenza statistica sufficiente per affermare che il corso abbia ridotto la media delle ore lavorate sotto le 40 ore.
Perché questo esercizio è un “caso scuola” per chiunque si occupi di gestione aziendale o HR:
1. La Potenza del Test Unidirezionale
In ambito accademico si usa spesso il test a due code per prudenza, ma nel mondo del business la domanda è quasi sempre: “Abbiamo migliorato rispetto a prima?”. Utilizzare un test a una coda permette di concentrare tutta la potenza statistica nella direzione che conta (la riduzione delle ore), rendendo il test più specifico per l’obiettivo aziendale.
2. La Severità di [math]\alpha = 0.01[/math]
Scegliere un livello di significatività dell’1% significa essere estremamente conservativi: stiamo dicendo che siamo disposti ad accettare solo l’1% di probabilità di dichiarare efficace un corso che in realtà non lo è (Errore di Tipo I).
In questo esercizio, la severità di [math]\alpha[/math] funge da “filtro anti-entusiasmo”, impedendo al management di cantare vittoria prematuramente davanti a un calo numerico che potrebbe essere solo frutto del caso.
3. ROI e Budget HR: Quando i numeri ingannano
Il passaggio da 40 a 38.2 ore sembra un risparmio del 4.5% del tempo, un dato che in una presentazione apparirebbe eccellente. Tuttavia, la statistica solleva un dubbio critico: “Questo risparmio è strutturale o è solo fortuna del campionamento?”.
- Costo dell’Incertezza: Se il campione è piccolo (15 persone) e la variabilità è alta, l’azienda rischia di scalare su 1000 dipendenti un corso che non funziona, sprecando budget e tempo.
- Lezione per il Management: Un risultato “non statisticamente significativo” non significa necessariamente che il corso sia inutile, ma che servono più dati (un campione più grande) o un effetto più marcato per giustificare l’investimento.
💡 Domanda di riflessione
Cosa cambierebbe nella nostra conclusione se avessimo utilizzato un livello di significatività [math]\alpha = 0.05[/math] invece di [math]0.01[/math]? Perché?
Risposta approfondita:
Se usassimo [math]\alpha = 0.05[/math], il valore critico per 14 gradi di libertà (unidirezionale) diventerebbe -1.761. Anche in questo caso, il nostro valore calcolato ([math]-1.367[/math]) resterebbe superiore al valore critico (ovvero “meno estremo”). Pertanto, la conclusione non cambierebbe: continueremmo a non rifiutare [math]H_0[/math].
Questo accade perché un [math]\alpha[/math] più grande rende il test “meno severo” (allarga la zona di rifiuto), ma nel nostro caso la deviazione standard del campione è così elevata rispetto alla differenza osservata (1.8 ore) che il risultato rimane non significativo.
Esercizio 3: Metodi di assemblaggio a confronto (Test t per due campioni indipendenti)
Testo dell’esercizio:
Un responsabile vuole confrontare l’efficienza di due metodi di assemblaggio. Vengono scelti 12 operai per il Metodo A e 10 per il Metodo B. Si assume che le popolazioni abbiano varianze uguali. Verificare se esiste una differenza significativa ([math]\alpha = 0.05[/math]).
- Metodo A: [math]n_A = 12, \bar{x}_A = 45.2[/math] sec, [math]s_A = 4.1[/math] sec
- Metodo B: [math]n_B = 10, \bar{x}_B = 41.5[/math] sec, [math]s_B = 3.8[/math] sec
Risoluzione
1. Definizione delle ipotesi
Test bilaterale (a due code):
- H₀: [math]\mu_A = \mu_B[/math] (I due metodi sono equivalenti).
- H₁: [math]\mu_A \neq \mu_B[/math] (Esiste una differenza significativa).
2. Calcolo della varianza “Pooled” ([math]s_p^2[/math])
Poiché assumiamo varianze uguali, combiniamo le varianze dei due campioni per ottenere una stima migliore:
[math]s_p^2 = \frac{(n_A – 1)s_A^2 + (n_B – 1)s_B^2}{n_A + n_B – 2}[/math]
[math]s_p^2 = \frac{(11 \cdot 4.1^2) + (9 \cdot 3.8^2)}{12 + 10 – 2} = \frac{184.91 + 129.96}{20} = 15.7435[/math]
[math]s_p = \sqrt{15.7435} \approx 3.968[/math]
3. Calcolo della statistica test [math]t[/math]
La formula per campioni indipendenti con varianza pooled è:
[math]\displaystyle t = \frac{\bar{x}_A – \bar{x}_B}{s_p \sqrt{\frac{1}{n_A} + \frac{1}{n_B}}}[/math]
[math]\displaystyle t = \frac{45.2 – 41.5}{3.968 \sqrt{\frac{1}{12} + \frac{1}{10}}} = \frac{3.7}{3.968 \cdot 0.428} \approx 2.179[/math]
4. Valore critico e Gradi di Libertà
- df: [math]n_A + n_B – 2 = 20[/math].
- Valore critico ([math]\alpha = 0.05[/math]): Per un test a due code con 20 df, il valore critico è [math]t_{crit} = \pm 2.086[/math].
5. Conclusione
Dato che il nostro valore calcolato [math]t = 2.179[/math] è maggiore di [math]2.086[/math], rifiutiamo l’ipotesi nulla.
Risultato: Esiste una differenza statisticamente significativa tra i due metodi. Il Metodo B risulta più efficiente (tempi di completamento inferiori).
Questo esercizio rappresenta il cuore del processo decisionale basato sui dati, trasformando la teoria in una competizione diretta tra strategie industriali.
1. Lo scenario dell’A/B Testing Fisico
Siamo di fronte alla versione “analogica” dell’A/B testing che i giganti del tech usano per le interfacce web. In questo caso, però, l’esperimento coinvolge risorse umane e tempi fisici. La varianza pooled è l’elemento chiave: ci permette di “unire le forze” dei due campioni per avere una visione più nitida della variabilità complessiva, a patto che i due metodi siano operativamente simili (stessa varianza).
2. Operations Management: Scegliere il “Campione”
A differenza dei test su un singolo campione, dove ci si confronta con uno standard storico, qui il responsabile delle Operations mette i processi uno contro l’altro. Non si tratta di capire se il Metodo B è “buono” in assoluto, ma se è migliore del Metodo A in modo affidabile.
- Decisioni Basate sul ROI: Se il Metodo B risparmia mediamente 3.7 secondi a pezzo e la statistica conferma che non è un caso, il manager può calcolare con precisione l’aumento della produttività giornaliera e giustificare il costo del passaggio al nuovo metodo.
3. Oltre l’uguaglianza apparente
In questo esercizio, la differenza tra le medie (45.2 vs 41.5) è supportata da una variabilità contenuta. Il fatto che il t calcolato (2.179) superi il t critico (2.086) è il “semaforo verde” per il cambiamento. Senza questo test, l’azienda potrebbe esitare, temendo che i 3 secondi di differenza siano solo dovuti alla bravura momentanea di uno dei gruppi di operai.
💡 Domanda di riflessione
Perché abbiamo usato una varianza “pooled” (combinata)? Cosa rappresenta e perché ha senso in questo contesto?
Risposta approfondita:
La varianza pooled è una media ponderata delle varianze dei due campioni. Ha senso usarla quando assumiamo che i due gruppi provengano da popolazioni con la stessa variabilità interna (omoschedasticità). Rappresenta la nostra “migliore stima” della varianza comune.
Utilizzandola, “fondiamo” le informazioni di entrambi i campioni per creare un errore standard più robusto. Se non potessimo assumere l’uguaglianza delle varianze, dovremmo ricorrere al test di Welch, che non usa la varianza pooled e corregge i gradi di libertà verso il basso per essere più conservativo.
Tabella dei Valori Critici t di Student
Usa questa tabella per trovare il valore critico in base ai Gradi di Libertà (df) e al livello di significatività alpha.
| Gradi di Libertà (df) | Unidirezionale α=0.05 / Bilaterale α=0.10 | Unidirezionale α=0.025 / Bilaterale α=0.05 | Unidirezionale α=0.01 / Bilaterale α=0.02 | Unidirezionale α=0.005 / Bilaterale α=0.01 |
| 1 | 6.314 | 12.706 | 31.821 | 63.657 |
| 5 | 2.015 | 2.571 | 3.365 | 4.032 |
| 10 | 1.812 | 2.228 | 2.764 | 3.169 |
| 14 (Es. 2) | 1.761 | 2.145 | 2.624 | 2.977 |
| 15 | 1.753 | 2.131 | 2.602 | 2.947 |
| 19 (Es. 1) | 1.729 | 2.093 | 2.539 | 2.861 |
| 20 (Es. 3) | 1.725 | 2.086 | 2.528 | 2.845 |
| 30 | 1.697 | 2.042 | 2.457 | 2.750 |
| 60 | 1.671 | 2.000 | 2.390 | 2.660 |
| ∞(Z) | 1.645 | 1.960 | 2.326 | 2.576 |
Come leggere la tabella per gli esercizi
Identifica i Gradi di Libertà ([math]df[/math]):
- Test a un campione: [math]df = n – 1[/math].
- Test a due campioni indipendenti: [math]df = n_A + n_B – 2[/math].
Scegli il tipo di Test:
- Se l’ipotesi è “diverso da” ([math]\mu \neq \mu_0[/math]), usa la colonna Bilaterale.
- Se l’ipotesi è “maggiore di” o “minore di”, usa la colonna Unidirezionale.
Incrocia i dati: Il valore trovato è la “soglia” oltre la quale il tuo risultato diventa statisticamente significativo.
Nota Tecnica: Noterai che per [math]df = \infty[/math], i valori della tabella [math]t[/math] coincidono esattamente con i valori della distribuzione normale standard ([math]Z[/math]). Questo perché, all’aumentare della dimensione del campione, la distribuzione [math]t[/math] “si stringe” fino a diventare una Gaussiana perfetta.
Articoli consigliati su Test t di Student
Questi articoli sono tutti correlati al tema dei Test t (di Student, t appaiato, t di Welch, ecc.) perché affrontano:
✅ le varianti teoriche del Test t per confrontare medie
✅ esercizi risolti passo-passo e confronti pratici
✅ casi d’uso reali per l’analisi statistica di dati aziendali
✅ esempi di codice Python/Scipy per implementazione reale
👉 Distribuzione t di Student: guida completa con test t bilaterale e unilaterale
👉 Test t appaiato: guida pratica con esempio, calcoli e codice Python/Scipy
👉 Statistica inferenziale: 8 esercizi progressivi (Z-test, t, p-value e potenza)
👉Test t di Welch: quando usarlo, formula ed esempi pratici
👉 Guida pratica al t-test di Welch: esercizi e soluzioni passo-passo





")