






Dopo aver esplorato come la Legge di Benford possa rivelare irregolarità statistiche nei dati finanziari, è naturale porsi una domanda più ampia:
come possiamo individuare anomalie quando i dati non seguono una distribuzione semplice o quando non sappiamo nemmeno cosa stiamo cercando?
Nel mondo reale, infatti, le frodi, gli errori e i comportamenti sospetti raramente si manifestano in modo lineare.
Un attacco informatico può sembrare solo “leggermente diverso” dal traffico normale.
Una transazione fraudolenta può avere importi apparentemente plausibili.
Un sensore industriale può iniziare a degradarsi molto prima di superare soglie critiche.
Ed è qui che entra in gioco uno degli algoritmi più intelligenti e sottovalutati del Machine Learning moderno:
Isolation Forest
Isolation Forest è un algoritmo di Machine Learning non supervisionato progettato per individuare anomalie.
La sua idea fondamentale è sorprendentemente semplice:
invece di imparare cosa è “normale”, prova a isolare ciò che è diverso.
Questa intuizione cambia completamente prospettiva rispetto a molti approcci classici.
Il Problema dell’Anomaly Detection
L’Anomaly Detection è l’arte di individuare elementi rari, sospetti o strutturalmente devianti rispetto al resto del dataset. I campi di applicazione sono critici:
-
Rilevamento frodi finanziarie
-
Cybersecurity e individuazione bot
-
Manutenzione predittiva industriale
-
Quality control nella manifattura
-
Medicina diagnostica
Il nodo da sciogliere è che, nella realtà operativa, i dati non hanno etichette. Le anomalie sono pochissime rispetto al rumore di fondo e mutano nel tempo. Applicare un classificatore standard è inutile: non possiamo addestrare un modello su una frode che non è mai avvenuta.
L’intuizione di Isolation Forest
Mentre la stragrande maggioranza degli algoritmi cerca di definire il perimetro del gregge, l’Isolation Forest cerca la pecora nera per isolarla.
La logica si basa su un’osservazione geometrica inconfutabile: le anomalie sono rare e diverse, quindi sono molto più facili da separare dal resto del gruppo.
Immagina un database clienti. La massa condividerà pattern simili (età comparabili, frequenza d’acquisto ordinaria, carrelli medi). Un’anomalia, come un acquisto compulsivo di beni di lusso alle tre del mattino, si troverà matematicamente ai margini di questo spazio multidimensionale. Se iniziamo a tracciare linee casuali per dividere i dati, le anomalie rimarranno da sole quasi subito.
Come funziona la Foresta
Isolation Forest costruisce decine di alberi decisionali casuali (iTree). Per ogni albero, il processo è brutale e veloce:
-
Seleziona una feature a caso (es. l’importo).
-
Sceglie un valore di “taglio” casuale tra il minimo e il massimo.
-
Divide il dataset in due e continua ricorsivamente finché ogni singolo punto non è isolato.
L’obiettivo non è prevedere, ma isolare. Un’osservazione normale richiederà dozzine di tagli prima di staccarsi dal blocco centrale. Un’anomalia, trovandosi in periferia, verrà separata in un paio di mosse.
In questo modello, la brevità del percorso nell’albero definisce il grado di anomalia.
L’Eleganza della Semplicità
Niente reti neurali pesanti, nessun calcolo delle distanze spaziali (che paralizza i server sui Big Data), nessuna assunzione sulle distribuzioni probabilistiche.
L’Isolation Forest domina perché:
-
È estremamente veloce: La complessità computazionale è lineare, rendendolo perfetto per analizzare milioni di righe in tempo reale.
-
È “cieco”: Lavorando senza etichette (unsupervised), intercetta le frodi “zero-day” che l’azienda non ha mai registrato prima.
-
Scala il multi-dimensionale: Le vere frodi emergono solo combinando variabili (importo + orario + posizione). Questo algoritmo gestisce centinaia di dimensioni senza sforzo.
Connessione Investigativa: Benford e la Foresta
Se hai già studiato la Legge di Benford (che individua anomalie statistiche nei pattern delle prime cifre numeriche), noterai un filo conduttore. Benford trova le anomalie matematiche; l’Isolation Forest trova quelle geometriche.
Entrambi si basano su un principio forense inviolabile: i comportamenti artificiali o forzati lasciano sempre tracce strutturali. I numeri inventati violano Benford; i comportamenti devianti si isolano troppo in fretta nella foresta.
Un esempio pratico in Python
Prima di visualizzare il grafico, il codice costruisce un piccolo scenario simulato di anomaly detection. Vengono generati artificialmente due gruppi di dati: una grande quantità di osservazioni “normali”, distribuite attorno a valori centrali, e un piccolo insieme di punti molto lontani dal comportamento standard, che rappresentano le anomalie.
Successivamente, il modello di viene addestrato sul dataset e assegna a ogni osservazione un’etichetta: 1 per i punti considerati normali e -1 per quelli identificati come anomali. Infine, il grafico colora i punti in blu o rosso per mostrare visivamente come l’algoritmo riesca a isolare le osservazioni sospette.
Installazione librerie
pip install numpy pandas matplotlib scikit-learn
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.ensemble import IsolationForest
# =========================
# CREAZIONE DATASET
# =========================
np.random.seed(42)
# dati normali
normal_data = np.random.randn(300, 2)
# anomalie artificiali
anomalies = np.random.uniform(
low=6,
high=8,
size=(15, 2)
)
# unione dataset
X = np.vstack([normal_data, anomalies])
# dataframe
df = pd.DataFrame(
X,
columns=['Feature_1', 'Feature_2']
)
# =========================
# MODELLO
# =========================
model = IsolationForest(
n_estimators=100,
contamination=0.05,
random_state=42
)
# training
model.fit(X)
# predizioni
df['anomaly'] = model.predict(X)
# =========================
# VISUALIZZAZIONE
# =========================
plt.figure(figsize=(10,6))
colors = df['anomaly'].map({
1: 'blue',
-1: 'red'
})
plt.scatter(
df['Feature_1'],
df['Feature_2'],
c=colors
)
plt.title('Isolation Forest - Rilevamento anomalie')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
print(df['anomaly'].value_counts())
plt.show()
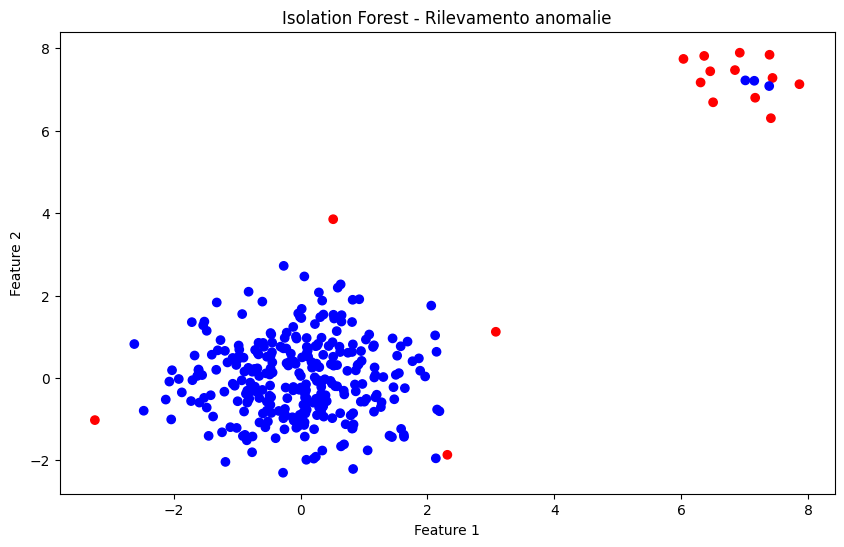
Il risultato mostrerà:
- punti blu → dati normali
- punti rossi → anomalie rilevate
Anatomia dei Parametri
model = IsolationForest( n_estimators=100, contamination=0.05, random_state=42 ):
n_estimators=100
Indica il numero di alberi decisionali “casuali” che comporranno la foresta.
- Ogni albero è costruito in modo indipendente.
- Ogni albero prova a isolare i punti del dataset tramite split casuali su feature e soglie.
- Il modello finale aggrega i risultati di tutti gli alberi.
Più alberi significano:
- maggiore stabilità delle stime;
- minore varianza del modello;
- migliore robustezza rispetto al rumore.
100 è un valore standard di compromesso tra prestazioni e costo computazionale.
contamination=0.05
È uno dei parametri più importanti dal punto di vista interpretativo.
Indica la proporzione attesa di anomalie nel dataset, in questo caso il 5%.
In pratica il modello usa questo valore per:
- definire una soglia di decisione;
- separare i punti normali dagli outlier;
- calibrare il “cut-off” dello score di anomalia.
Effetto pratico:
- circa il 5% dei punti verrà classificato come anomalo (-1);
- il restante 95% come normale (1).
È un parametro delicato:
- se troppo alto → troppi falsi positivi;
- se troppo basso → anomalie perse (falsi negativi).
random_state=42
Serve a rendere riproducibile il risultato.
Poiché Isolation Forest utilizza:
- selezioni casuali delle feature
- soglie random sugli split
senza un seed fisso ogni esecuzione produrrebbe risultati leggermente diversi.
Impostando:
random_state=42
si garantisce che:
- la costruzione degli alberi sia replicabile;
- i risultati siano identici tra esecuzioni;
- l’analisi sia scientificamente verificabile.
Il valore 42 è convenzionale (pop-culture), ma potrebbe essere qualsiasi intero.
In sintesi
Questa configurazione definisce una foresta di 100 alberi casuali che cercano di isolare i punti del dataset, assumendo che circa il 5% delle osservazioni sia anomalo, e garantendo che tutto il processo sia riproducibile in modo deterministico.
Commento dell’output
Il grafico prodotto da Isolation Forest permette di visualizzare in modo estremamente intuitivo il funzionamento dell’algoritmo.
La grande nuvola centrale di punti blu rappresenta le osservazioni considerate “normali” dal modello. In questo esempio simulato, tali dati sono stati generati attorno allo zero tramite una distribuzione casuale gaussiana (np.random.randn()), per cui tendono naturalmente a concentrarsi in una regione relativamente compatta dello spazio cartesiano.
I punti rossi, invece, rappresentano le anomalie rilevate dall’algoritmo. Queste osservazioni si trovano molto distanti dal comportamento medio del dataset e vengono isolate rapidamente dagli alberi casuali costruiti da Isolation Forest.
Ed è proprio questo il concetto matematico fondamentale:
più un punto richiede poche suddivisioni per essere separato dagli altri, più è probabile che sia anomalo.
Nel nostro caso, i punti artificialmente generati tra i valori 6 e 8 risultano estremamente lontani dalla distribuzione principale centrata attorno a 0.
Di conseguenza:
- bastano pochi “tagli” casuali nello spazio dei dati per isolarli;
- la profondità media dei nodi negli alberi risulta molto bassa;
- il modello assegna quindi l’etichetta
-1.
Al contrario, i punti normali richiedono molte più suddivisioni prima di essere completamente separati dagli altri elementi del dataset. Questo porta a percorsi medi più lunghi negli alberi decisionali, caratteristica tipica delle osservazioni considerate coerenti con la struttura statistica generale dei dati.
Un aspetto interessante è che Isolation Forest non utilizza alcuna conoscenza semantica del problema.
L’algoritmo non “sa” cosa siano frodi, errori o attacchi informatici. Si limita a individuare elementi geometricamente rari nello spazio multidimensionale.
Questo approccio è particolarmente potente nei contesti reali, dove le anomalie:
- possono assumere forme imprevedibili;
- cambiano nel tempo;
- non seguono regole fisse;
- sono spesso assenti nei dataset storici etichettati.
Dal punto di vista operativo, il grafico evidenzia anche un altro concetto importante della Data Science moderna:
le anomalie non sono necessariamente errori.
Un outlier può infatti rappresentare:
- una frode;
- un comportamento eccezionale;
- un cambio di regime;
- un nuovo pattern emergente;
- oppure semplicemente rumore statistico.
Per questo motivo, nei sistemi reali, Isolation Forest viene spesso utilizzato come primo livello di screening automatico: il modello segnala osservazioni sospette che vengono poi analizzate da sistemi più complessi o da analisti umani.
Infine, il parametro:
contamination=0.05ha un ruolo fondamentale nell’interpretazione dell’output. In questo esempio stiamo dicendo al modello che circa il 5% dei dati potrebbe essere anomalo. L’algoritmo utilizza questa informazione per stabilire la soglia oltre la quale classificare un punto come outlier.
Se il valore fosse troppo alto, il modello produrrebbe molti falsi positivi.
Se fosse troppo basso, rischierebbe invece di non identificare anomalie reali.
Questo mostra un aspetto cruciale dell’Anomaly Detection:
l’efficacia del modello dipende non solo dall’algoritmo, ma anche dalla comprensione statistica del dominio applicativo.
Commento all’Esercizio e Applicazioni di Business
Dal punto di vista puramente esecutivo, l’esercizio è scolastico: genera due blob separati e li colora. Ma le sue implicazioni pratiche sono brutali.
Ciò che rende questo esercizio potente è il concetto del model.fit(X).
A differenza della classificazione supervisionata (dove devi passare model.fit(X, Y) dicendo all’algoritmo chi è il buono e chi il cattivo), qui la variabile Y non esiste.
L’algoritmo ha “imparato” a trovare le anomalie lavorando completamente alla cieca. Non ha calcolato le distanze euclidee tra i punti (che è un calcolo pesantissimo [math]O(N^2)[/math]), ma ha solo diviso lo spazio a caso.
Nel mondo reale, questa mappa a dispersione potrebbe rappresentare i log di accesso a un server aziendale:
Feature 1: Numero di file scaricati in un’ora.
Feature 2: Dimensione dei pacchetti criptati.
Il “blob” blu centrale rappresenta i dipendenti che lavorano normalmente. I punti rossi a destra sono i due computer infettati da ransomware che stanno esfiltrando dati. L’algoritmo non sa cosa sia un ransomware; sa solo che quei computer stanno facendo qualcosa di spazialmente isolato rispetto agli altri 300 colleghi.
E in un reparto di sicurezza IT, un allarme del genere, generato in pochi millisecondi e senza bisogno di database storici delle firme virali, fa la differenza tra un incidente evitato e un disastro aziendale.
Dalla Foresta alla Decision Intelligence: perché l’anomalia è una decisione che sta per accadere
A questo punto, dopo aver visto come Isolation Forest individua ciò che è raro nello spazio dei dati, è naturale fare un passo ulteriore: capire cosa significa operativamente rilevare un’anomalia.
Nel mondo reale, un outlier non è un punto rosso su un grafico. È una decisione latente, un evento che sta per produrre conseguenze operative, economiche o di sicurezza. Ogni anomalia è un bivio: ignorarla significa lasciare che il sistema decida da solo; intercettarla significa riprendere il controllo.
Ed è qui che Isolation Forest incontra la Decision Intelligence.
1. L’anomalia come informazione causale
La Decision Intelligence non si limita a rilevare deviazioni: le interpreta. Un’anomalia non è un errore, ma l’effetto di una causa nascosta:
- un cambio di comportamento del cliente
- un attacco informatico in fase iniziale
- un sensore che anticipa un guasto
- un processo che sta deragliando
Isolation Forest fornisce il segnale. La Decision Intelligence costruisce il perché e il cosa fare dopo.
2. Dal rilevamento all’azione: il ciclo decisionale
In un sistema decisionale moderno, la pipeline è chiara:
- Osservazione → l’algoritmo isola il punto sospetto
- Interpretazione → un modello causale valuta scenari e ipotesi
- Ottimizzazione → si calcola la risposta migliore
- Azione → il sistema interviene o avvisa un analista
Isolation Forest copre il primo step. La Decision Intelligence orchestra gli altri tre.
È il passaggio dalla previsione alla prescrizione.
3. L’anomalia come early warning aziendale
In un contesto reale, un outlier è un allarme. E gli allarmi, se integrati in un sistema decisionale, diventano:
- riduzione del rischio
- prevenzione dei guasti
- ottimizzazione dei costi
- protezione degli asset digitali
- miglioramento continuo dei processi
Isolation Forest è il sensore. La Decision Intelligence è il sistema nervoso.
4. Perché Isolation Forest è perfetto per la Decision Intelligence
Tre motivi strutturali:
- È veloce → ideale per sistemi decisionali in tempo reale
- È non supervisionato → intercetta eventi mai visti prima
- È scalabile → funziona su decine di feature e milioni di righe
In altre parole: è un algoritmo progettato per ambienti dove le decisioni devono essere prese prima che il problema diventi evidente.
5. Verso sistemi autonomi di decisione
La Decision Intelligence non è un modello: è un’architettura. E in questa architettura, gli algoritmi di anomaly detection sono:
- gli occhi che vedono ciò che sfugge
- le antenne che captano il rumore
- i radar che individuano traiettorie anomale
Isolation Forest non dice cosa sta accadendo. Dice dove guardare. E in un mondo dominato da complessità, questo è già metà della decisione.
In sintesi
Isolation Forest è molto più di un algoritmo: è un meccanismo di attenzione per sistemi decisionali intelligenti.
La Decision Intelligence prende quel segnale, lo collega a modelli causali, valuta scenari, ottimizza alternative e trasforma un punto rosso in una decisione migliore.
È il passaggio dalla foresta alla strategia.
Articoli di approfondimento
👉Legge di Benford e Data Science: la matematica che smaschera le frodi nei dati
👉La scienza delle scelte: dentro la Decision Intelligence
👉Decision Intelligence: l’ingegneria della scelta ottima tra modelli causali e incertezza
👉Scoprire la manipolazione dei prezzi: strategie per definire una soglia critica efficace
👉L’arte di mentire con la statistica (e perché ci caschiamo ogni volta)


: Esempi Pratici e Calcoli")


