Gli annunci pubblicitari ci aiutano a mantenere questo sito gratuito e accessibile a tutti. Ti saremmo davvero grati se volessi disattivare AdBlocker per il nostro sito: niente pubblicità invasive, promesso! Grazie per il tuo supporto ❤️Our team work realy hard to produce quality content on this website and we noticed you have ad-blocking enabled.
Rilevazione Anomalie in Python con Isolation Forest: Guida ed Esercizi
Trovare un ago in un pagliaio è difficile, ma individuare un ago che si nasconde fingendosi un filo di paglia è l’incubo di ogni analista.
Quando si lavora con dati reali, che si tratti di transazioni bancarie o di log di un server, i comportamenti fraudolenti o i guasti tecnici non si presentano quasi mai con un cartello di avviso.
Spesso sono anomalie silenziose, mimetizzate in mezzo a milioni di operazioni legittime.
Invece di mappare faticosamente la normalità per poi procedere per esclusione, l’algoritmo Isolation Forest ribalta completamente la prospettiva: punta a isolare direttamente ciò che è insolito sfruttando la sua stessa rarità.
Nelle righe che seguono vedremo in azione questo algoritmo attraverso tre scenari pratici, analizzando il codice e le scelte architetturali necessarie per farlo funzionare sul campo.
Pubblicità
Esercizio 1 – Rilevazione di anomalie in transazioni finanziarie (livello facile)
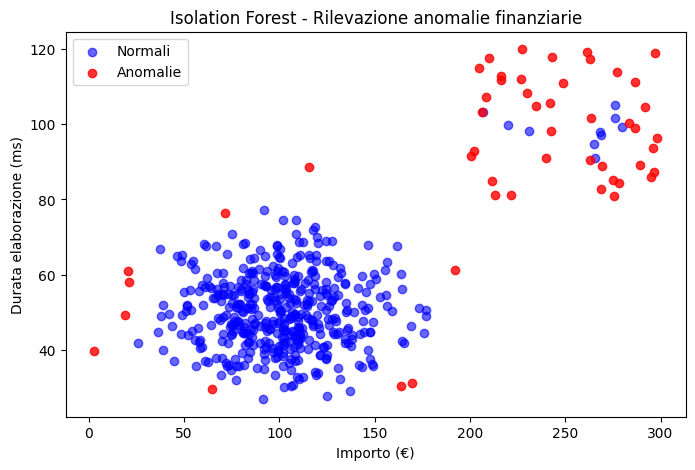
Testo Sei un data scientist in una startup fintech. Hai a disposizione un dataset simulato di 500 transazioni con 2 caratteristiche:
importo (€) e durata_elaborazione (ms).
La maggior parte delle transazioni è normale (cluster centrale), ma alcune sono fraudolente e si trovano lontane.
Usa IsolationForest di scikit-learn per identificare le anomalie, visualizza il risultato con un grafico a dispersione e stampa il numero di outlier trovati.
💡 Osservazione Isolation Forest isola le anomalie sfruttando il fatto che, in media, un punto anomalo richiede un numero minore di split (partizioni) per essere separato dagli altri.
Il parametro contamination indica la proporzione attesa di outlier (qui 10%).
❓ Domanda di riflessione Quale proprietà matematica dell’algoritmo rende più efficiente l’isolamento di un outlier rispetto a un punto normale?
Esercizio 2 – Influenza del parametro max_samples e contamination (livello facile‑intermedio)
Testo In un progetto di cybersecurity su 2000 accessi a un server, devi bilanciare sensibilità e specificità.
Crea un dataset con 5% di outlier noti.
Sperimenta diversi valori di contamination (0.02, 0.05, 0.1) e max_samples (0.5, 1.0).
Per ogni combinazione calcola il numero di outlier rilevati e confrontalo con il reale. Quale combinazione si avvicina di più alla verità? Spiega perché max_samples ridotto può essere vantaggioso.
💡 Osservazione max_samples < 1.0 usa un sottoinsieme casuale dei dati per costruire ogni albero. Questo riduce il rischio di “mascheramento” degli outlier in presenza di molti campioni normali, ed inoltre accelera l’addestramento.
Isolation Forest opera con confronti diretti dei valori. Se le scale sono molto diverse (es. temperatura ~70, vibrazione ~0.3), una feature potrebbe dominare gli split. La standardizzazione rende le feature numericamente comparabili.
One‑hot encoding
Le variabili categoriali vengono trasformate in colonne binarie. Isolation Forest non soffre la “maledizione della dimensionalità” perché ogni split considera una sola feature alla volta. Le colonne binarie aggiunte sono perfettamente gestibili.
Vantaggio della Pipeline
La pipeline garantisce che le trasformazioni (standardizzazione, one‑hot) vengano apprese solo sui dati di addestramento e poi riapplicate allo stesso modo in predict. Evita data leakage e rende il codice robusto per futuri test su nuovi dati.
Parametro contamination
Qui impostato a 0.05 (5%) perché abbiamo iniettato 40 outlier su 800 campioni = 5%. In un caso reale senza etichette, va stimato con conoscenza del dominio o con analisi della distribuzione dei punteggi.
❓ Domanda di riflessione
Quale caratteristica di Isolation Forest evita che l’aggiunta di molte variabili binarie (derivanti da one‑hot encoding) degradi le prestazioni, a differenza di quanto accade nei metodi basati su distanza come k‑NN o LOF?
RISPOSTE ALLE DOMANDE DI RIFLESSIONE
Esercizio 1
Proprietà matematica: Isolation Forest si basa sul concetto che gli outlier sono “pochi e diversi”. In media, un punto anomalo richiede meno split per essere isolato (percorso più corto nell’albero) perché si trova in regioni a bassa densità. La lunghezza del percorso normalizzata viene usata come punteggio di anomalia.
Esercizio 2
Se contamination è troppo basso: Il modello sottostimerà la percentuale di outlier. Molte vere anomalie verranno classificate come normali (aumento falsi negativi). Al contrario, se contamination è troppo alto, si avranno molti falsi positivi. In assenza di etichette, contamination va stimato con conoscenza del dominio o tramite analisi della distribuzione dei punteggi.
Isolation Forest seleziona una feature casuale ad ogni split, quindi le feature irrilevanti vengono semplicemente ignorate (bassa probabilità di essere scelte). Nei metodi basati su distanza, tutte le dimensioni contribuiscono al calcolo della distanza, causando l’appiattimento delle differenze (curse of dimensionality).
Analisi Applicativa
Esercizio 1: L’Intuizione Visiva della Densità
Questo esercizio mappa perfettamente la teoria dello spazio dei dati. Utilizzando due sole dimensioni (importo e durata), permette di generare un grafico a dispersione bidimensionale immediato.
Perché è interessante: Serve a scardinare il bias cognitivo secondo cui le anomalie si trovano sempre “oltre una certa soglia” (es. sopra i 200€). Isolation Forest non taglia il dataset in modo lineare; isola i punti che richiedono meno partizioni casuali. Questo esercizio dimostra visivamente che l’anomalia è un concetto spaziale e di densità, non un semplice valore massimo.
Esercizio 2: L’Ingegneria dei Parametri e l’Effetto Mascheramento
Qui si entra nel vivo del tuning dei modelli di cybersecurity, dove i falsi positivi possono paralizzare un team di Security Operations Center (SOC).
Perché è interessante: Introduce il concetto cruciale di swamping (falsi positivi) e masking (falsi negativi). Mostra che configurare contamination=0.1 quando l’attacco reale è del 5% raddoppia i falsi positivi (da 19 a 109), creando rumore inutile. Inoltre, l’analisi su max_samples evidenzia come il sotto-campionamento non sia solo un trucco per velocizzare il calcolo, ma una tecnica matematica per evitare che cluster di outlier troppo vicini si “protegano” a vicenda dall’isolamento.
Esercizio 3: L’Architettura di Produzione (Mondo Reale)
I sensori di fabbrica (IoT) sputano fuori dati grezzi e disomogenei. Isolare i difetti di produzione richiede l’unione di telemetria e metadati logistici.
Perché è interessante: Dal punto di vista ingegneristico è l’esercizio più maturo. Dimostra come l’uso combinato di ColumnTransformer e Pipeline prevenga il data leakage e renda il modello industrializzabile (pronto per ricevere dati in streaming tramite API senza rompersi). Spiega inoltre un paradosso: anche se Isolation Forest non si basa sulle distanze (quindi non soffrirebbe intrinsecamente della scala dei dati), la standardizzazione pre-addestramento serve a dare lo stesso “peso probabilistico” alle feature numeriche durante la scelta casuale dei nodi di split.
Errori comuni da evitare sul campo
Lavorare con algoritmi non supervisionati come Isolation Forest è liberatorio, ma nasconde alcune trappole sottili che possono compromettere i risultati in produzione.
Trattare il parametro contamination come una costante magica: Impostare il valore di default (spesso 0.1) senza un’analisi preliminare è rischioso. Se il tasso reale di frodi nella tua azienda è dello 0.05\%, un valore di contamination=0.1 sommergerà il team di analisti con il 99.9\% di falsi positivi. Se non hai etichette storiche, analizza la distribuzione dei punteggi di anomalia (score_samples) per individuare il ginocchio della curva prima di fissare la soglia.
Ignorare i dati mancanti (NaN):IsolationForest di scikit-learn non gestisce nativamente i valori mancanti. Se passi un dataset con dei NaN, l’algoritmo si interromperà con un errore. È obbligatorio inserire un passo di imputazione (es. SimpleImputer o KNNImputer) all’interno della pipeline prima del preprocessore.
Abusare della dimensionalità con dati a elevata cardinalità: Sebbene Isolation Forest sia robusto rispetto a k-NN in presenza di molte colonne, applicare il OneHotEncoder su una variabile categorica con migliaia di valori distinti (es. gli ID dei comuni italiani) crea una matrice sparsa gigantesca. In questo scenario, la probabilità che l’algoritmo scelga split casuali su colonne popolate quasi interamente da zeri è altissima, distruggendo l’efficacia del modello. In questi casi, preferisci tecniche come il Target Encoding o la riduzione della dimensionalità.
Non esiste l’algoritmo perfetto per ogni anomalia. Spesso la scelta dipende dalla struttura geometrica dei dati e dai vincoli computazionali dell’infrastruttura.
Algoritmo
Approccio
Complessità Computazionale
Ottimale per…
Punto Debole
Isolation Forest
Isolamento tramite partizionamento casuale (Alberi)
Lineare [math]O(n)[/math]
Grandi dataset, dataset tabulari a medio-alta dimensionalità.
Fatica a identificare anomalie locali circondate da cluster a densità variabile.
LOF (Local Outlier Factor)
Densità locale basata sulla distanza dei [math]k[/math] vicini
Quadratica [math]O(n^2)[/math]
Identificare anomalie locali (punti insoliti rispetto ai vicini immediati, anche in cluster densi).
Estremamente lento su grandi volumi di dati; soffre la maledizione della dimensionalità.
One-Class SVM
Confine geometrico (Kernel trick) massimizzando il margine
Da quadratica a cubica [math]O(n^2 \text{ a } n^3)[/math]
Dati ad altissima dimensionalità (es. testo, embeddings, immagini) e confini complessi.
Sensibile al rumore e molto difficile da calibrare (iperparametri [math]\gamma[/math] e [math]\nu[/math]).
Framework Decisionale: Quando scegliere Isolation Forest?
Per evitare di procedere per tentativi, puoi utilizzare questo sintetico schema decisionale prima di scrivere la prima riga di codice:
🟩 Scegli Isolation Forest se:
I volumi di dati sono elevati: Hai centinaia di migliaia o milioni di righe. La complessità lineare di Isolation Forest lo rende uno dei pochi algoritmi in grado di girare in tempi umani senza cluster di calcolo enormi.
L’anomalia è globale: L’outlier si trova chiaramente distante da tutti i gruppi principali di dati (es. una transazione da 50.000€ quando la media aziendale è 80€).
Hai poche risorse hardware: Devi far girare il modello direttamente su macchine con risorse limitate (es. un container leggero o un’istanza serverless).
🟥 Evita Isolation Forest (e valuta alternative) se:
Le anomalie dipendono dal contesto locale: Un valore è anomalo solo se confrontato con il suo gruppo specifico, ma risulterebbe normale se confrontato con l’intero dataset (in questo scenario, usa LOF).
Lavori con dati non strutturati puri: Se devi trovare anomalie in flussi audio, immagini mediche o testi complessi, i metodi basati su Deep Learning (come gli Autoencoder) o le One-Class SVM offrono prestazioni nettamente superiori grazie alla capacità di catturare relazioni non lineari complesse.











")
