Gli annunci pubblicitari ci aiutano a mantenere questo sito gratuito e accessibile a tutti. Ti saremmo davvero grati se volessi disattivare AdBlocker per il nostro sito: niente pubblicità invasive, promesso! Grazie per il tuo supporto ❤️Our team work realy hard to produce quality content on this website and we noticed you have ad-blocking enabled.
La Distribuzione F di Fisher e l’Analisi della Varianza (ANOVA)
Introduzione pratica: Perché ci interessa la Distribuzione F?
Immaginiamo di essere i responsabili di un’azienda che vende tre diversi tipi di fertilizzanti per piante. Vogliamo capire se c’è una differenza significativa nella crescita media delle piante in base al tipo di fertilizzante utilizzato. Per farlo, raccogliamo dati sulla crescita media delle piante in tre gruppi distinti, ciascuno trattato con un diverso fertilizzante. La domanda che ci poniamo è: le differenze osservate nelle medie dei tre gruppi sono dovute a una reale efficacia differente dei fertilizzanti o sono solo il risultato della variabilità casuale?
Qui entra in gioco l’Analisi della Varianza (ANOVA), che utilizza la Distribuzione F di Fisher per confrontare le varianze dei gruppi e determinare se le differenze nelle medie sono statisticamente significative.
Intuizione dietro l’ANOVA:
L’Analisi della Varianza (ANOVA) potrebbe sembrare controintuitiva, dato che il suo obiettivo è confrontare le medie, ma il suo nome si riferisce all’analisi della varianza. Il motivo di questo approccio risiede in una logica semplice ma potente. Immagina di avere diversi gruppi di dati. Se le medie di questi gruppi sono molto diverse tra loro, i valori all’interno di ciascun gruppo tenderanno a raggrupparsi attorno alla propria media, e le medie dei gruppi saranno distanti l’una dall’altra. Questo si traduce in una grande variabilità tra le medie dei gruppi.
Al contrario, se le medie dei gruppi sono simili, i valori di tutti i gruppi tenderanno a mescolarsi, e la variabilità tra le medie dei gruppi sarà relativamente piccola rispetto alla variabilità che osserviamo all’interno di ciascun gruppo a causa della naturale dispersione dei dati.
In sostanza, l’ANOVA confronta due tipi di variabilità:
Varianza tra i gruppi: Quanto le medie dei diversi gruppi sono diverse dalla media complessiva. Una grande varianza tra i gruppi suggerisce che le medie dei gruppi non sono uguali.
Varianza entro i gruppi: Quanto i dati all’interno di ciascun gruppo sono dispersi attorno alla propria media. Questa varianza rappresenta la variabilità “naturale” o l’errore casuale nei dati.
Se la varianza tra i gruppi è significativamente più grande della varianza entro i gruppi, ciò fornisce evidenza che le differenze osservate tra le medie dei gruppi non sono semplicemente dovute al caso, ma riflettono un reale effetto del fattore che stiamo studiando (nel nostro esempio, il tipo di fertilizzante). Il test F nell’ANOVA quantifica proprio questo rapporto tra la varianza tra i gruppi e la varianza entro i gruppi.
La Distribuzione F di Fisher: Definizione
La Distribuzione F di Fisher è una distribuzione di probabilità utilizzata nei test di ipotesi per confrontare due varianze campionarie. Si definisce come il rapporto tra due variabili casuali indipendenti distribuite secondo una chi-squared, ciascuna normalizzata per i rispettivi gradi di libertà:
[math]s_1^2[/math] e [math]s_2^2[/math] sono le varianze campionarie dei due gruppi,
[math]\nu_1[/math] e [math]\nu_2[/math] sono i rispettivi gradi di libertà.
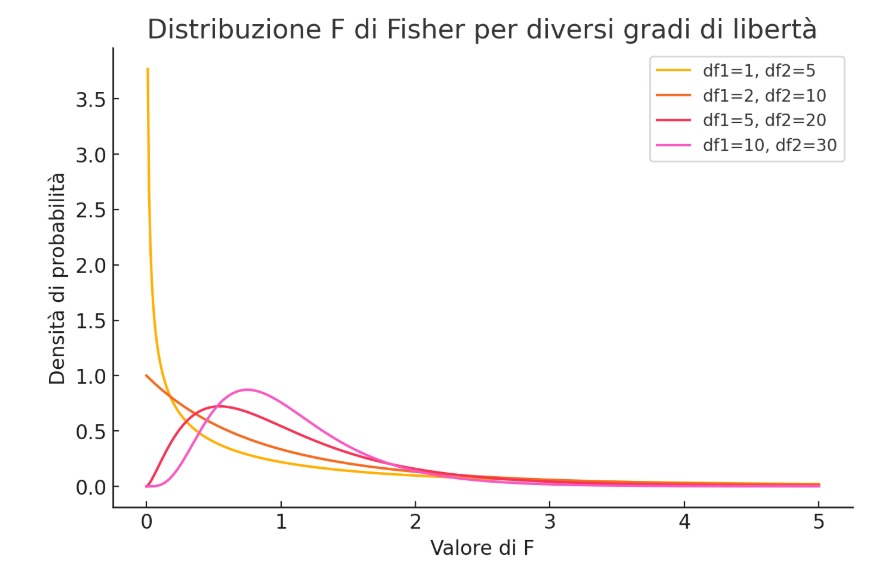
La distribuzione F ha due parametri: [math]\nu_1[/math] (gradi di libertà del numeratore) e [math]\nu_2[/math] (gradi di libertà del denominatore). La sua forma dipende da questi due parametri e è asimmetrica, con valori sempre positivi.
il grafico che mostra la distribuzione F per diversi gradi di libertà ([math]df_1, df_2[/math]). Si nota come la forma della distribuzione cambi a seconda dei parametri, diventando più simmetrica con valori più alti di [math]df_1[/math] e [math]df_2[/math].
Test statistici basati sulla distribuzione F
Test per il confronto di due varianze (F-test)
Questo test è utilizzato per confrontare due varianze campionarie e verificare se provengono dalla stessa popolazione.
Ipotesi:
[math]H_0: \sigma_1^2 = \sigma_2^2[/math]
[math]H_1: \sigma_1^2 \neq \sigma_2^2[/math] (o [math]>[/math] o [math]<[/math])
Statistica test:
[math]F = \frac{s_1^2}{s_2^2}[/math]
Regola di decisione:
Confrontare il valore calcolato di [math]F[/math] con i valori critici della distribuzione [math]F(\nu_1 – 1, \nu_2 – 1)[/math] o calcolare il p-value.
ANOVA (Analisi della Varianza)
L’Analisi della Varianza (ANOVA) utilizza la distribuzione [math]F[/math] per verificare se le medie di più gruppi sono uguali.
Statistica test:
[math]F = \frac{MSB}{MSW}[/math]
dove [math]MSB[/math] è la media dei quadrati tra i gruppi e [math]MSW[/math] è la media dei quadrati all’interno dei gruppi.
Se [math]F[/math] è maggiore di un valore critico o il p-value è inferiore al livello di significatività scelto (ad esempio, 0.05), si rifiuta l’ipotesi nulla e si conclude che almeno una media è diversa dalle altre.
Test di Levene
Il test di Levene verifica l’omoschedasticità, ovvero l’uguaglianza delle varianze tra più gruppi.
Si basa su una trasformazione dei dati, calcolando i valori assoluti degli scarti dalla media per confrontare le varianze tra gruppi. Se il test indica che le varianze non sono uguali, l’ANOVA classica potrebbe non essere appropriata, e si potrebbe optare per una versione robusta come l’ANOVA di Welch.
Perché i risultati di un’ANOVA siano validi e interpretabili, è fondamentale che i dati soddisfino alcune assunzioni chiave:
Indipendenza delle osservazioni: Questa assunzione implica che le misurazioni o i dati raccolti per un’unità sperimentale (ad esempio, una pianta) non devono influenzare le misurazioni di altre unità. Nel nostro esempio, la crescita di una pianta trattata con un fertilizzante non dovrebbe influenzare la crescita di un’altra pianta, indipendentemente dal fertilizzante utilizzato. La violazione di questa assunzione può portare a conclusioni errate sul significato delle differenze tra i gruppi.
Normalità dei residui: I residui sono le differenze tra il valore osservato di una variabile e la media del suo gruppo. L’ANOVA assume che questi residui siano approssimativamente normalmente distribuiti all’interno di ciascun gruppo. Questa assunzione è particolarmente importante per campioni di piccole dimensioni. Se i residui non sono normali, i risultati del test F potrebbero non essere affidabili. Si possono utilizzare test di normalità (come il test di Shapiro-Wilk o il test di Kolmogorov-Smirnov) e ispezionare grafici (come gli istogrammi o i grafici quantile-quantile) per verificare questa assunzione.
Omoschedasticità (uguaglianza delle varianze): Questa assunzione richiede che le varianze delle popolazioni da cui provengono i diversi gruppi siano uguali. In altre parole, la dispersione dei dati attorno alla media dovrebbe essere simile in tutti i gruppi. Il test di Levene, che hai già menzionato, è uno strumento statistico utilizzato proprio per verificare questa assunzione. Se il test di Levene indica una violazione dell’omoschedasticità (cioè, le varianze non sono uguali), l’ANOVA classica potrebbe non essere appropriata. In questi casi, si possono considerare diverse alternative:
ANOVA di Welch: Questa è una versione robusta dell’ANOVA che non assume l’uguaglianza delle varianze. È più affidabile quando le varianze dei gruppi sono diverse e le dimensioni dei campioni non sono uguali.
Trasformazioni dei dati: A volte, applicare una trasformazione matematica ai dati (come la trasformazione logaritmica o la radice quadrata) può aiutare a stabilizzare le varianze e rendere i dati più conformi alle assunzioni dell’ANOVA.
Test non parametrici: Se le assunzioni di normalità e omoschedasticità sono gravemente violate e le trasformazioni non aiutano, si potrebbe considerare l’utilizzo di test non parametrici come il test di Kruskal-Wallis, che non si basa su queste assunzioni.
È importante verificare queste assunzioni prima di interpretare i risultati di un’ANOVA. La violazione di una o più di queste assunzioni può mettere in discussione la validità delle conclusioni tratte dall’analisi.
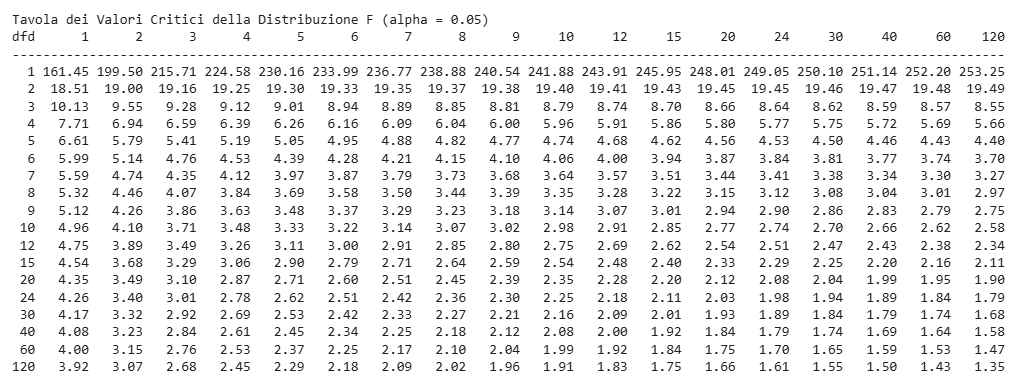
Le tavole forniscono i valori critici per diversi livelli di significatività ([math]\alpha[/math]) e gradi di libertà ([math]df_1, df_2[/math]).
Esempio:
Per [math]\alpha = 0.05[/math], [math]df_1 = 3[/math], [math]df_2 = 16[/math], il valore critico è [math]F_{0.05}(3, 16) \approx 3.24[/math].
Se [math]F_{calcolato} > F_{critico}[/math], si rifiuta [math]H_0[/math].
Attenzione:
Per [math]\alpha/2[/math] (test bilaterali), cercare [math]F_{\alpha/2}[/math] e [math]F_{1-\alpha/2} = 1/F_{\alpha/2}(df_2, df_1)[/math].
Codice Python per generare e visualizzare una tabella dei valori critici della distribuzione F
import pandas as pd
from import pandas as pd
from scipy.stats import f
def genera_tavola_valori_critici_f_formato_allineato(alpha_values, dfn_values, dfd_values):
"""
Genera e mostra a video una tabella dei valori critici della distribuzione F
nel formato desiderato con colonne allineate.
Args:
alpha_values (list): Lista dei livelli di significatività (alpha).
dfn_values (list): Lista dei gradi di libertà del numeratore.
dfd_values (list): Lista dei gradi di libertà del denominatore.
"""
for alpha in alpha_values:
print(f"\nTavola dei Valori Critici della Distribuzione F (alpha = {alpha})")
# Larghezza fissa per la colonna 'dfd'
dfd_width = 3
# Larghezza fissa per le colonne dei valori critici
value_width = 6
header = ["dfd".rjust(dfd_width)] + [str(dfn).rjust(value_width) for dfn in dfn_values]
print(" ".join(header))
print("-" * (dfd_width + 1 + len(" ".join([str("-" * value_width) for _ in dfn_values]))))
for dfd in dfd_values:
row = [str(dfd).rjust(dfd_width)]
for dfn in dfn_values:
critical_value = f.ppf(1 - alpha, dfn, dfd)
row.append(f"{critical_value:.2f}".rjust(value_width))
print(" ".join(row))
if __name__ == "__main__":
# Definisci i valori desiderati per alpha, dfn e dfd
alpha_livelli = [0.05, 0.01]
gradi_liberta_numeratore = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 12, 15, 20, 24, 30, 40, 60, 120]
gradi_liberta_denominatore = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 12, 15, 20, 24, 30, 40, 60, 120]
# Genera e mostra la tavola dei valori critici con allineamento
genera_tavola_valori_critici_f_formato_allineato(alpha_livelli, gradi_liberta_numeratore, gradi_liberta_denominatore)
Struttura Tipica di una Tavola dei Valori Critici della Distribuzione F:
Una tavola dei valori critici della distribuzione F è generalmente organizzata in questo modo:
Righe: Rappresentano i gradi di libertà del denominatore ([math]df_2[/math] o talvolta indicati come [math]\nu_2[/math]).
Colonne: Rappresentano i gradi di libertà del numeratore ([math]df_1[/math] o talvolta indicati come [math]\nu_1[/math]).
Valori all’interno della tabella: Questi valori sono i valori critici di F per un dato livello di significatività ([math]\alpha[/math]). Solitamente, ci sono più tabelle, una per ogni livello di significatività comune (ad esempio, [math]\alpha = 0.05[/math], [math]\alpha = 0.01[/math], [math]\alpha = 0.10[/math], ecc.). A volte, la stessa tabella può contenere più livelli di significatività indicati in diverse sezioni o con simboli diversi.
Identificare il Livello di Significatività ([math]\alpha[/math]): Questo valore (solitamente 0.05, 0.01 o 0.10) è stabilito prima di eseguire il test e rappresenta la probabilità massima di rifiutare l’ipotesi nulla quando è vera.
Determinare i Gradi di Libertà:
Gradi di libertà del numeratore ([math]df_1[/math]): Dipendono dal test specifico.
Per l’ANOVA con [math]k[/math] gruppi, [math]df_1 = k – 1[/math].
Per l’F-test per confrontare due varianze, [math]df_1 = n_1 – 1[/math] (dove [math]n_1[/math] è la dimensione del campione del gruppo con la varianza nel numeratore).
Gradi di libertà del denominatore ([math]df_2[/math]): Dipendono dal test specifico.
Per l’ANOVA, [math]df_2 = N – k[/math] (dove [math]N[/math] è la dimensione totale del campione).
Per l’F-test per confrontare due varianze, [math]df_2 = n_2 – 1[/math] (dove [math]n_2[/math] è la dimensione del campione del gruppo con la varianza nel denominatore).
Trovare la Tavola Corrispondente al Livello di Significatività: Se hai scelto [math]\alpha = 0.05[/math], devi utilizzare la tabella specifica per quel livello di significatività.
Individuare il Valore Critico:
Cerca la riga corrispondente ai gradi di libertà del denominatore ([math]df_2[/math]).
Cerca la colonna corrispondente ai gradi di libertà del numeratore ([math]df_1[/math]).
Il valore all’intersezione di questa riga e colonna è il valore critico di F per il tuo test al livello di significatività scelto.
Confrontare la Statistica Test con il Valore Critico:
Calcola la statistica test F dal tuo campione di dati.
Se la statistica test F è maggiore del valore critico trovato nella tabella, allora rifiuti l’ipotesi nulla. Questo significa che c’è una probabilità inferiore a [math]\alpha[/math] di osservare un valore di F così estremo se l’ipotesi nulla fosse vera.
Se la statistica test F è minore o uguale al valore critico, allora non rifiuti l’ipotesi nulla. Questo non significa che l’ipotesi nulla sia vera, ma semplicemente che non hai abbastanza evidenza dai tuoi dati per rifiutarla al livello di significatività scelto.
Test a una Coda (Right-Tailed):La maggior parte dei test F (come nell’ANOVA e nel confronto di due varianze quando l’ipotesi alternativa è che una varianza è maggiore dell’altra) sono intrinsecamente test a una coda (right-tailed). Questo perché la statistica F è un rapporto di varianze che sono sempre non negative. Un valore di F grande indica che la varianza nel numeratore è significativamente maggiore di quella nel denominatore.In questo caso, utilizzi direttamente il valore critico trovato nella tabella corrispondente al livello di significatività [math]\alpha[/math] scelto. Se la tua statistica test F cade nella regione critica (cioè, è maggiore del valore critico), rifiuti l’ipotesi nulla.
Applicazione della Distribuzione F nell’ANOVA
L’Analisi della Varianza (ANOVA) viene utilizzata per confrontare le medie di più gruppi, determinando se almeno una di esse è significativamente diversa dalle altre.
L’ipotesi nulla ([math]H_0[/math]) dell’ANOVA afferma che tutte le medie dei gruppi sono uguali:
[math]
H_0: \mu_1 = \mu_2 = \dots = \mu_k
[/math]
L’ipotesi alternativa ([math]H_1[/math]) afferma che almeno una media è diversa:
[math]
H_1: \exists i, j \text{ tale che } \mu_i \neq \mu_j
[/math]
Per verificare questa ipotesi, si calcola il rapporto tra la variabilità tra i gruppi (Mean Square Between, MSB) e la variabilità all’interno dei gruppi (Mean Square Within, MSW):
[math]F = \frac{MSB}{MSW}[/math]
dove:
[math]MSB[/math] misura la variazione tra le medie dei gruppi,
[math]MSW[/math] misura la variazione all’interno dei gruppi.
Se il valore di [math]F[/math] è sufficientemente grande, si rigetta l’ipotesi nulla e si conclude che almeno un gruppo ha una media significativamente diversa dalle altre.
Post-hoc Test
Quando l’ANOVA restituisce un risultato significativo, indicando che esiste una differenza tra le medie di almeno due gruppi, non specifica quali gruppi particolari differiscono tra loro. Per identificare quali coppie di medie sono significativamente diverse, è necessario ricorrere a ulteriori analisi chiamate test post-hoc (o confronti multipli). Questi test vengono eseguiti dopo aver riscontrato un effetto significativo con l’ANOVA. Esistono diversi tipi di test post-hoc, ognuno con le proprie caratteristiche e assunzioni, come il test di Tukey’s Honestly Significant Difference (HSD), il test di Bonferroni, il test di Sidak e molti altri. La scelta del test post-hoc appropriato dipende dalle specifiche domande di ricerca e dalle caratteristiche dei dati.
Esempio Pratico
Supponiamo di avere i seguenti dati sulla crescita media delle piante (in cm) per tre fertilizzanti:
dove [math]N – k[/math] sono i gradi di libertà residui.
Calcolo della statistica F:
[math]F = \frac{MSB}{MSW}[/math]
Se il valore di [math]F[/math] supera il valore critico della distribuzione F, con [math]k – 1[/math] e [math]N – k[/math] gradi di libertà, allora possiamo concludere che almeno una media è significativamente diversa dalle altre.
Utilizzo della Tavola dei Valori Critici:
Dobbiamo confrontare la nostra statistica F calcolata (37.00) con il valore critico della distribuzione F per un livello di significatività [math]\alpha = 0.05[/math].
I gradi di libertà del numeratore sono [math]df_1 = k – 1 = 3 – 1 = 2[/math].
I gradi di libertà del denominatore sono [math]df_2 = N – k = 9 – 3 = 6[/math].
Ora, guardiamo la tabella dei valori critici della distribuzione F (alpha = 0.05) . Cerchiamo l’intersezione tra la colonna con [math]dfn = 2[/math] (gradi di libertà del numeratore) e la riga con [math]dfd = 6[/math] (gradi di libertà del denominatore).
Dalla tabella, il valore critico per [math]F_{0.05}(2, 6)[/math] è 5.14.
7. Confronto e Conclusione:
La nostra statistica F calcolata è 37.00.
Il valore critico dalla tabella è 5.14.
Poiché la statistica F calcolata (37.00) è maggiore del valore critico (5.14), rifiutiamo l’ipotesi nulla. Basandoci su questo test ANOVA e utilizzando la tabella dei valori critici, concludiamo che esiste una differenza statisticamente significativa nella crescita media delle piante tra almeno uno dei tre tipi di fertilizzanti al livello di significatività del 5%.
Dal Punto di Vista Teorico:
L’ANOVA si basa sull’idea di partizionare la variabilità totale dei dati in diverse fonti di variazione. In questo caso, la variabilità totale nella crescita delle piante è suddivisa in:
Variazione tra i gruppi: Questa variazione riflette quanto le medie dei tre gruppi di fertilizzanti differiscono tra loro. Se i fertilizzanti hanno effetti diversi sulla crescita, ci aspetteremmo una grande variabilità tra le medie dei gruppi. Questa variabilità è quantificata da MSB.
Variazione entro i gruppi: Questa variazione riflette la variabilità naturale o l’errore casuale all’interno di ciascun gruppo di piante trattate con lo stesso fertilizzante. Anche se le piante ricevono lo stesso trattamento, la loro crescita non sarà identica. Questa variabilità è quantificata da MSW.
L’ANOVA confronta queste due fonti di variazione attraverso il rapporto F.
Ipotesi Nulla ([math]H_0[/math]): Afferma che non c’è alcun effetto significativo del tipo di fertilizzante sulla crescita media delle piante. In altre parole, le medie delle popolazioni da cui provengono i tre campioni sono uguali ([math]\mu_1 = \mu_2 = \mu_3[/math]).
Ipotesi Alternativa ([math]H_1[/math]): Afferma che almeno uno dei tipi di fertilizzante ha un effetto diverso sulla crescita media delle piante. Cioè, almeno una media di popolazione è diversa dalle altre.
Se la variabilità tra i gruppi (MSB) è significativamente maggiore della variabilità entro i gruppi (MSW), suggerisce che le differenze osservate nelle medie dei gruppi non sono semplicemente dovute al caso, ma riflettono un vero effetto del fattore (il tipo di fertilizzante).
La Distribuzione F è la distribuzione teorica che ci dice quanto è probabile ottenere un certo valore di F se l’ipotesi nulla fosse vera. Il valore critico della Distribuzione F è una soglia. Se la nostra statistica F calcolata supera questo valore critico, significa che è improbabile che abbiamo osservato tali differenze tra le medie dei gruppi se i fertilizzanti non avessero alcun effetto. Pertanto, rifiutiamo l’ipotesi nulla e concludiamo che almeno un fertilizzante è diverso dagli altri in termini di effetto sulla crescita delle piante.
Conclusione
La Distribuzione F di Fisher è uno strumento fondamentale in statistica inferenziale per confrontare varianze e determinare se esistono differenze significative tra gruppi. L’ANOVA, che si basa su questa distribuzione, è ampiamente utilizzata in ricerca scientifica, marketing, industria e medicina per confrontare gruppi e prendere decisioni basate sui dati.
Saper interpretare correttamente un test F, un’ANOVA e il test di Levene è essenziale per chiunque lavori con dati quantitativi e voglia trarre conclusioni affidabili da esperimenti e analisi statistiche.








: Guida Completa con Esercizi Pratici e Calcoli Dettagliati")
")
")
: Guida Completa con Esempio Pratico e Interpretazione")