






Sono le 18:00. Il magazzino ha appena chiuso le preparazioni e, puntuale come ogni sera, sulla tua scrivania virtuale atterra un file Excel con gli ordini della giornata. Fin qui tutto bene, se non fosse che i costi per spedire quella merce non sono scritti da nessuna parte: dipendono dalle tariffe dinamiche del corriere, calcolate in base a peso, volume, zone disagiate e rincari carburante.
In molte aziende, questo è il momento in cui qualcuno apre il gestionale, copia e incolla i dati a mano sul portale del trasportatore e prega di non fare errori. Oppure, ci si affida a macro Excel scritte anni fa, pronte a bloccarsi al primo calo di connessione.
Lavorare con i dati aziendali significa quasi sempre avere a che fare con sistemi imperfetti e frammentati. In questo articolo non vedremo un ecosistema ordinato e teorico, ma affronteremo un problema reale. Costruiremo una pipeline ETL (Extract, Transform, Load) robusta usando Python, Pandas e SQLite. L’obiettivo?
Automatizzare il calcolo dei costi via API, gestire i fallimenti di rete senza far crollare lo script e restituire report puliti a chi deve prendere decisioni finanziarie.
Lo scenario applicativo
Per comprendere appieno il valore del codice che abbiamo strutturato, dobbiamo calarlo nel “mondo reale”. Non stiamo parlando di un semplice esercizio didattico, ma di un problema che si presenta quotidianamente nella pancia operativa di e-commerce mediamente strutturati, distributori wholesale o aziende manifatturiere.
Gli Attori in Gioco
Dietro questo script ci sono tre entità aziendali che hanno bisogno di comunicare tra loro, ognuna con obiettivi diversi:
- L’Ufficio Logistica / Magazzino: Gestisce fisicamente la merce. A fine giornata estrae dal sistema gestionale (ERP) la lista dei colli pronti, salvandola in un file Excel (
ordini.xlsx). Conosce il destinatario, il peso e l’ingombro, ma non ha visibilità in tempo reale sulle tariffe spot del corriere. - Il Corriere Esterno (es. DHL, FedEx, BRT): Non lavora più con tabelle cartacee fisse. Calcola i costi di spedizione dinamicamente tramite algoritmi proprietari che tengono conto di carburante, zone disagiate, combinazione peso/volume e saturazione dei mezzi. Mette a disposizione un’API REST per quotare ogni singolo collo.
- Il Controllo di Gestione / Amministrazione: Ha un obiettivo categorico: la riconciliazione dei costi. Deve sapere esattamente quanto costerà ogni singola spedizione prima che arrivi la fattura a fine mese, sia per imputare correttamente i costi ai vari centri di profitto, sia per accorgersi immediatamente di eventuali anomalie di fatturazione.
Il Flusso Operativo Quotidiano
Immaginiamo la routine aziendale in cui si inserisce la nostra pipeline ETL:
Ore 18:00 – L’estrazione dei dati
Il magazzino chiude le preparazioni. Il gestionale genera il file ordini.xlsx. È un file “vivo” e, come spesso accade con i dati inseriti parzialmente a mano o da sistemi diversi, contiene imperfezioni: un peso non rilevato dalla bilancia, un codice d’ordine formattato male, o un volume pari a zero.
Ore 18:15 – L’esecuzione dello Script
La nostra pipeline Python entra in azione (spesso agganciata a un sistema di automazione notturna).
- Legge l’Excel e inizia a martellare l’API del corriere.
- Se l’API ha un micro-down di 500 millisecondi, il nostro meccanismo di retry salva l’operazione: aspetta e riprova, evitando che l’intero processo fallisca per un glitch di rete.
- Se l’ordine è strutturalmente errato (l’ordine ORD-2026-008 con il peso mancante), lo script non si ferma per l’errore. Isola il problema, scrive la motivazione nel database SQLite e passa oltre.
Ore 18:20 – La biforcazione degli Output
Lo script termina e produce due risultati distinti per due destinatari diversi:
- All’Amministrazione arriva il file
ordini_con_costo.xlsx. È pulito, completo e pronto per essere importato nel software di contabilità o nei cruscotti di Business Intelligence per l’analisi dei margini. - Al Supervisore del Magazzino arriva il file
report_anomalie.xlsx. Contiene solo le righe scartate (es. l’ordine 008) con il motivo del fallimento esplicito (“Dati mancanti: peso o dimensioni non validi”).
L’Architettura del Flusso
Prima di scrivere il codice, è fondamentale visualizzare come i dati si muovono attraverso i vari componenti del sistema, dal file di input fino alla persistenza dei log e alla generazione dei report operativi.
[ ordini.xlsx ]
│
▼
[ Pandas ]
│
▼
┌───────────┐ Tentativi falliti (Retry automatico)
│ Chiama │ ───────────────────────────────────────────┐
│ API │ <──────────────────────────────────────────┘
└─────┬─────┘
│ Successo / Fallimento Definitivo
▼
┌───────────┐
│ Estrazione│ ──► Costo Spedizione ──► [ ordini_con_costo.xlsx ]
│ Dati │ ──► Errore/Log ──► [ SQLite (log_spedizioni) ]
└───────────┘ │
▼
[ report_anomalie.xlsx ]1. Generazione dei Dati di Test
Creiamo un file Excel simulato (ordini.xlsx). Inseriremo di proposito un’anomalia (None sul peso di un ordine) per testare la capacità del codice di reagire ai dati mancanti.
import pandas as pd
def crea_file_ordini_simulato(nome_file="ordini.xlsx"):
dati_mock = {
"ID_Ordine": [
"ORD-2026-001", "ORD-2026-002", "ORD-2026-003",
"ORD-2026-004", "ORD-2026-005", "ORD-2026-006",
"ORD-2026-007", "ORD-2026-008", "ORD-2026-009"
],
"Peso_kg": [
1.5, 12.35, 0.45,
45.0, 5.8, 2.1,
18.5, None, 82.4 # Il 'None' genererà un errore controllato
],
"Dimensioni_cm3": [
1200, 8500, 350,
42000, 3100, 1800,
15000, 600, 95000
]
}
df = pd.DataFrame(dati_mock)
df.to_excel(nome_file, index=False, engine="openpyxl")
print(f"File '{nome_file}' generato con successo.")
if __name__ == "__main__":
crea_file_ordini_simulato()2. Il Motore di Integrazione con Retry Logico
Per evitare di dipendere da librerie esterne solo per la gestione delle eccezioni, definiamo una classe dedicata (ShippingAPIError). Inoltre, implementiamo un vero ciclo di retry con attesa temporizzata per superare eventuali micro-interruzioni di rete.
import pandas as pd
import sqlite3
from datetime import datetime
import time
import logging
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
class ShippingAPIError(Exception):
"""Eccezione personalizzata per errori di comunicazione o logica dell'API Spedizioni."""
pass
def simula_api_costo(peso, dimensioni):
"""Calcolo fittizio del costo di spedizione con regole di business."""
if pd.isna(peso) or pd.isna(dimensioni):
raise ValueError("Dati mancanti: peso o dimensioni non validi")
if peso > 100:
raise ShippingAPIError("Peso eccessivo per la spedizione standard")
costo = (peso * 0.5) + (dimensioni * 0.001)
return round(costo, 2)
def chiama_api_costo(peso, dimensioni, max_retry=3, delay=1):
"""Chiama l'API ed esegue tentativi multipli in caso di errore di rete simulato."""
for tentativo in range(1, max_retry + 1):
try:
return simula_api_costo(peso, dimensioni)
except ValueError as e:
# Gli errori di validazione del dato sono bloccanti: inutile riprovare
raise
except ShippingAPIError as e:
# Errore di business (es. peso > 100): il retry non cambierà il risultato
raise
except Exception as e:
# Errori generici (es. timeout di rete simulato)
logging.warning(f"Tentativo {tentativo}/{max_retry} fallito: {e}. Riprovo tra {delay}s...")
if tentativo == max_retry:
raise ShippingAPIError(f"API non raggiungibile dopo {max_retry} tentativi.")
time.sleep(delay)
def elabora_ordini(file_input="ordini.xlsx", file_output="ordini_con_costo.xlsx"):
df = pd.read_excel(file_input, engine="openpyxl")
logging.info(f"Lette {len(df)} righe da {file_input}")
conn = sqlite3.connect("spedizioni.db")
cursor = conn.cursor()
cursor.execute('''
CREATE TABLE IF NOT EXISTS log_spedizioni (
id INTEGER PRIMARY KEY AUTOINCREMENT,
id_ordine TEXT NOT NULL,
timestamp TEXT NOT NULL,
costo REAL,
errore TEXT
)
''')
conn.commit()
costi = []
log_buffer = [] # Buffer per ottimizzare le prestazioni del database
for index, row in df.iterrows():
id_ordine = row["ID_Ordine"]
peso = row["Peso_kg"]
dim = row["Dimensioni_cm3"]
errore = None
costo = None
try:
costo = chiama_api_costo(peso, dim)
logging.info(f"Ordine {id_ordine} elaborato: costo = {costo}€")
except Exception as e:
errore = str(e)
logging.error(f"Ordine {id_ordine} fallito: {errore}")
# Accumuliamo i dati nel buffer invece di fare un commit a ogni riga
log_buffer.append((id_ordine, datetime.now().isoformat(), costo, errore))
costi.append(costo)
# Scrittura massiva (Bulk Insert) per ottimizzare l'I/O
cursor.executemany(
"INSERT INTO log_spedizioni (id_ordine, timestamp, costo, errore) VALUES (?, ?, ?, ?)",
log_buffer
)
conn.commit()
conn.close()
df["CostoSpedizione"] = costi
df.to_excel(file_output, index=False)
logging.info(f"File {file_output} creato con successo. Avvio reportistica...")
genera_report_anomalie()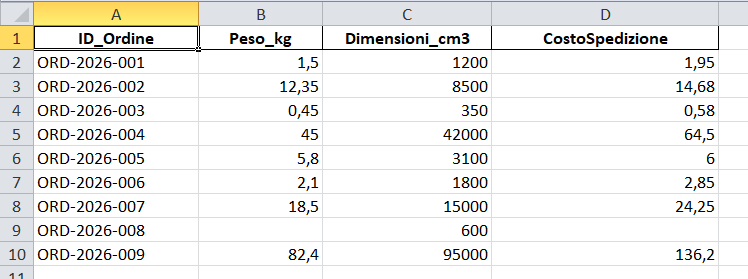
3. Estrazione Automatica del Report Anomalie
Per isolare i record problematici, interroghiamo lo storico di SQLite. Poiché il database memorizza lo storico di tutte le esecuzioni precedenti (Audit Trail), estraiamo solo l’ultimo errore registrato per ciascun ordine, evitando duplicati visivi nel report finale.
def genera_report_anomalie(db_name="spedizioni.db", file_report="report_anomalie.xlsx"):
"""Estrae l'ultima anomalia registrata per ogni ordine ed esporta il report."""
conn = sqlite3.connect(db_name)
# Query con sotto-selezione per isolare solo l'ultimo stato di ogni ordine
query = """
SELECT id_ordine, timestamp, errore
FROM log_spedizioni
WHERE errore IS NOT NULL
AND id IN (SELECT MAX(id) FROM log_spedizioni GROUP BY id_ordine)
"""
df_anomalie = pd.read_sql_query(query, conn)
conn.close()
if df_anomalie.empty:
print(f"\n[{datetime.now().strftime('%Y-%m-%d %H:%M:%S')}] ELABORAZIONE COMPLETATA: Nessuna anomalia riscontrata.")
return None
print(f"\n⚠️ ATTENZIONE: Rilevate {len(df_anomalie)} anomalie attive nell'ultima elaborazione.")
print("-" * 60)
print(df_anomalie.to_string(index=False))
print("-" * 60)
df_anomalie.to_excel(file_report, index=False, engine="openpyxl")
print(f"💾 Report operativo delle eccezioni salvato in: '{file_report}'")
return df_anomalie
Ora che il motore gira in locale, vediamo come connetterlo al mondo esterno:
Dalla Simulazione a una Vera API REST
Nel nostro esempio abbiamo utilizzato la funzione simula_api_costo() per rendere l’articolo completamente riproducibile senza dipendere da servizi esterni. In un contesto aziendale reale, tuttavia, il costo di spedizione verrebbe generalmente richiesto a un sistema esterno tramite API REST messe a disposizione dal corriere o dal provider logistico.
La buona notizia è che l’architettura costruita finora richiede modifiche minime: è sufficiente sostituire la funzione di simulazione con una chiamata HTTP reale.
import requests
def chiama_api_reale(peso, dimensioni):
response = requests.post(
"https://api.corriere.it/costo",
json={
"peso": peso,
"dimensioni": dimensioni
},
timeout=5
)
response.raise_for_status()
dati = response.json()
return dati["costo"]Dal punto di vista della pipeline, il resto del codice può rimanere invariato.
La funzione chiama_api_costo() continuerebbe a gestire:
- timeout di rete;
- tentativi multipli (retry);
- logging degli errori;
- registrazione nel database SQLite;
- generazione dei report operativi.
In altre parole, l’intero sistema è stato progettato seguendo il principio di separazione delle responsabilità: la logica di integrazione con il servizio esterno è isolata e può essere sostituita senza modificare il resto del flusso ETL.
Questo approccio è particolarmente importante quando si lavora con servizi di terze parti come:
- API dei corrieri (DHL, FedEx, UPS, BRT);
- sistemi ERP;
- piattaforme e-commerce;
- gateway di pagamento;
- CRM aziendali.
Una corretta separazione tra logica di business e logica di integrazione rende il codice più robusto, manutenibile e facilmente adattabile all’evoluzione dei sistemi esterni.
Analisi dei Costi di Spedizione: Dalla Pipeline al Controllo di Gestione
Fino a questo punto abbiamo costruito una pipeline capace di acquisire, validare e archiviare i dati. Ma una pipeline ETL non crea valore semplicemente spostando informazioni da un sistema all’altro. Il vero vantaggio emerge quando quei dati vengono trasformati in indicatori utili per il controllo di gestione e il processo decisionale.
Grazie alla colonna CostoSpedizione generata dalla pipeline, possiamo calcolare alcuni indicatori fondamentali per il monitoraggio logistico.
import pandas as pd
df = pd.read_excel("ordini_con_costo.xlsx")
# Escludiamo gli ordini che non hanno prodotto un costo valido
df_validi = df.dropna(subset=["CostoSpedizione"])
costo_totale = df_validi["CostoSpedizione"].sum()
costo_medio = df_validi["CostoSpedizione"].mean()
costo_mediano = df_validi["CostoSpedizione"].median()
costo_massimo = df_validi["CostoSpedizione"].max()
print(f"Costo totale: {costo_totale:.2f} €")
print(f"Costo medio: {costo_medio:.2f} €")
print(f"Costo mediano: {costo_mediano:.2f} €")
print(f"Costo massimo: {costo_massimo:.2f} €")Per il dataset utilizzato nell’esempio otteniamo:
| Indicatore | Valore |
|---|---|
| Costo Totale | 251,01 € |
| Costo Medio | 31,38 € |
| Costo Mediano | 10,34 € |
| Costo Massimo | 136,20 € |
Perché la Media da Sola Può Essere Fuorviante?
Osserviamo una differenza significativa tra media e mediana:
- Costo medio: 31,38 €
- Costo mediano: 10,34 €
Questo accade perché una singola spedizione particolarmente onerosa (136,20 €) trascina verso l’alto la media.
In presenza di distribuzioni asimmetriche, molto comuni nella logistica, la mediana rappresenta spesso una misura più affidabile del costo “tipico” sostenuto dall’azienda.
Individuazione Automatica delle Spedizioni Anomale
Una semplice analisi statistica può aiutare a individuare spedizioni potenzialmente anomale o da verificare.
q1 = df_validi["CostoSpedizione"].quantile(0.25)
q3 = df_validi["CostoSpedizione"].quantile(0.75)
iqr = q3 - q1
soglia_superiore = q3 + 1.5 * iqr
anomalie = df_validi[
df_validi["CostoSpedizione"] > soglia_superiore
]
print(anomalie[["ID_Ordine", "CostoSpedizione"]])Questo approccio utilizza l’Interquartile Range (IQR), una tecnica molto diffusa nei sistemi di monitoraggio e controllo qualità per identificare valori fuori scala rispetto al comportamento normale dei dati.
Dal Reporting Operativo alla Business Intelligence
Una volta archiviati in SQLite, i dati delle spedizioni possono alimentare dashboard e KPI come:
- costo logistico medio per ordine;
- costo medio per chilogrammo spedito;
- incidenza delle spese di trasporto sul fatturato;
- distribuzione dei costi per area geografica;
- trend mensile dei costi logistici;
- identificazione automatica di anomalie e picchi di spesa.
In questo modo una semplice pipeline ETL diventa il primo mattone di un sistema di Logistics Analytics, capace di trasformare dati operativi grezzi in informazioni utili per il controllo di gestione e l’ottimizzazione dei processi aziendali.

Dietro le Quinte del Codice: Perché non è il “solito” script Python
Se guardiamo questo esercizio dal punto di vista dell’ingegneria del software, ci accorgiamo che risolve problemi che nei tutorial di base vengono solitamente ignorati. La vera peculiarità di questa pipeline non risiede nell’uso di Pandas per leggere un Excel, ma nell’architettura difensiva che è stata implementata.
Ecco i tre pilastri che rendono questo codice pronto per il mondo reale:
La separazione tra “Errori di Rete” ed “Errori di Dominio”
Quando si chiama un’API, le cose si rompono. Sempre. Ma come si rompono fa la differenza. Se manca la connessione per un istante, riprovare ha senso (Errore Transitorio). Se l’ordine pesa 150 kg e il limite è 100, riprovare 1000 volte non cambierà il risultato (Errore di Business). Aver creato una gerarchia di eccezioni con try-except condizionali fa sì che il nostro script non perda tempo inutilmente, ma non si arrenda nemmeno alla prima difficoltà di rete.
Il Pattern “Buffer & Bulk Insert” per le performance
In un contesto didattico, è comune vedere una query INSERT seguita da un COMMIT all’interno di un ciclo for. Nel mondo reale, questa pratica distrugge i dischi e rallenta l’esecuzione in modo esponenziale. Accumulare i log in memoria (nella lista log_buffer) per scaricarli nel database relazionale SQLite in un’unica transazione con executemany() è un Design Pattern che garantisce scalabilità, permettendo di processare 10.000 righe nello stesso tempo che ne richiederebbero 100 con l’approccio ingenuo.
L’Idempotenza e l’Audit Trail Operativo
Nel mondo logistico, chi tocca i dati deve lasciare una traccia. Scrivere le anomalie in un database relazionale anziché limitarsi a un noioso e illeggibile file .log di testo puro, ci permette di interrogare la storia. Grazie alla sotto-query SQL implementata (SELECT MAX(id) ... GROUP BY id_ordine), estraiamo sempre l’ultimo stato noto, senza generare rumore o falsi allarmi, mantenendo intatto lo storico dei tentativi falliti per eventuali analisi post-mortem dell’IT.
Questo è il passaggio fondamentale da “scrivere script” a “progettare soluzioni”.
Data Engineering, Python, Database e Automazione
👉Analizzare CSV giganti in Python: Pandas e chunksize
👉SQLite3 in Python: da zero a Pandas, best practice e integrazione
👉Crittografia con Fernet in Python per Data Engineering
👉2026: l’era di PyArrow e i nuovi formati colonnari
👉Excel e Python: automazione e potenziamento dei workflow di analisi dati
👉Python per Data Engineering: esercizi reali su Excel, API e automazione
👉Ottimizza vendite e marketing: probabilità, break-even e Python/Excel

 è il futuro della Data Analysis")


")